
深度学习图像算法工程师面试前总结(包括基础点和项目实现点)
这篇内容主要写了自己简历相关的技能点的了解(百度一下记录下来)和自己项目梳理一下需要注意的点。
1.深度学习
参考https://www.cnblogs.com/xyou/p/10112156.html
深度学习可以被定义为以下四个基本网络框架中具有大量参数和层数的神经网络:
无监督预训练网络卷积神经网络循环神经网络递归神经网络
卷积神经网络(Convolutional Neural Network)基本上就是用共享权重在空间中进行扩展的标准神经网络。卷积神经网络主要是通过内部卷积来识别图片,内部卷积可以看到图像上识别对象的边缘。
循环神经网络(Recurrent Neural Network)基本上就是在时间上进行扩展的标准神经网络,它提取进入下一时间步的边沿,而不是在同一时间进入下一层。循环神经网络主要是为了识别序列,例如语音信号或者文本。其内部的循环意味着网络中存在短期记忆。
递归神经网络(Recursive Neural Network)更类似于分层网络,其中输入序列没有真正的时间面,但是必须以树状方式分层处理。以下10种方法均可应用于这些框架。
2.深度学习常用的算法(我简历当中写比较熟悉的)

随机梯度下降
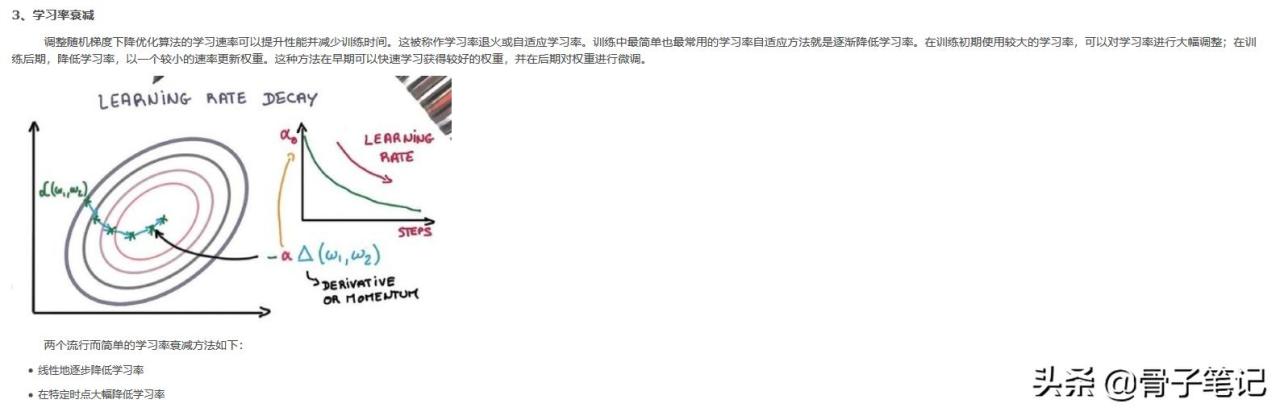
学习率衰减

Dropout

最大池

批量标准化

迁移学习
3.熟悉常用的图像处理算法
(1)边缘检测:
先来一起看看边缘检测的一般步骤吧。
滤波:边缘检测的算法主要是基于图像强度的一阶和二阶导数,但导数通常对噪声很敏感,因此必须采用滤波器来改善与噪声有关的边缘检测器的性能。常见的滤波方法主要有高斯滤波,即采用离散化的高斯函数产生一组归一化的高斯核,然后基于高斯核函数对图像灰度矩阵的每一点进行加权求和。
增强:增强边缘的基础是确定图像各点邻域强度的变化值。增强算法可以将图像灰度点邻域强度值有显著变化的点凸显出来。在具体编程实现时,可通过计算梯度幅值来确定。
检测:经过增强的图像,往往邻域中有很多点的梯度值比较大,而在特定的应用中,这些点并不是我们要找的边缘点,所以应该采用某种方法来对这些点进行取舍。实际工程中,常用的方法是通过阈值化方法来检测。
Canny边缘检测算法的处理流程:
图像灰度化:只有灰度图才能进行边缘检测。
使用高斯滤波器,以平滑图像,滤除噪声。
计算图像中每个像素点的梯度强度和方向。
应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散响应。
应用双阈值(Double-Threshold)检测来确定真实的和潜在的边缘。
通过抑制孤立的弱边缘最终完成边缘检测。
(2)图像增强:
python中PIL模块中有一个叫做ImageEnhance的类,该类专门用于图像的增强处理,不仅可以增强(或减弱)图像的亮度、对比度、色度,还可以用于增强图像的锐度。
图像几何变换通常包括图像的平移、翻转、旋转等操作,利用图像几何操作实现图像数据增强。
加噪|Noise:对图像加噪音是一种有趣的图像增强技术,现在我开始对这类操作变得更加熟悉。我已经看过很多关于对抗网络训练的有趣论文,当将一些噪音加入到图像后,模型无法对图像进行正确分类。我仍然在寻找能产生比下图更好的加噪方法。添加噪声可能有助于使得畸变更加明显,并使得模型更加鲁棒。
4.熟悉opencv
图像数字化:灰度图像数字化,彩色图像数字化几何变换:投影变换,极坐标变换对比度增强:灰度直方图,线性变换,直方图正规化,伽马变换,全局直方图均衡化图像平滑:高斯平滑,均值平滑,中值平滑阈值分割:Otsu阈值分割形态学处理:腐蚀和膨胀,开运算(先腐蚀后膨胀)和闭运算边缘检测:Roberts算子,Sobel边缘检测, Canny边缘检测,Laplacian算子几何形状的检测:霍夫圆和霍夫直线检测
5.计算机视觉
图像分类:为图片中出现的物体目标分类出其所属类别的标签,如画面中的人、楼房、街道、车辆等;目标检测:将图片或者视频中感兴趣的目标提取出来,对于导盲系统来说,各类的车辆、行人、交通标识、红绿灯都是需要关注的对象;图像语义分割:将视野中的车辆和道路勾勒出来是必要的,这需要图像语义分割技术作为支撑,勾勒出图像物体中的前景物体的轮廓;场景文字识别:道路名、绿灯倒计时秒数、商店名称等,这些文字对于导盲功能的实现也是至关重要的。
以上已经包括了计算机视觉(CV)领域的四大任务,在CV领域主要有八项任务,其他四大任务包括:图像生成、人体关键点检测、视频分类、度量学习等。
目标检测的模型:
R-CNNFast R-CNNFaster R-CNNMask R-CNNSSD (Single Shot MultiBox Defender)YOLO (You Only Look Once)
6.机器学习常用算法
(1)k均值

(2)最小二乘法实质就是最小化“均方误差”,而均方误差就是残差平方和的1/m(m为样本数),同时均方误差也是回归任务中最常用的性能度量。
最小二乘法的基本原则是:最优拟合直线应该使各点到直线的距离的和最小,也可表述为距离的平方和最小。
(3)岭回归
一般线性回归是最小二乘法回归,残差计算是平方误差项。岭回归(Ridge Regression)是在平方误差的基础上增加正则项,通过确定的值可以使得在方差和偏差之间达到平衡:随着的增大,模型方差减小而偏差增大。
岭回归是对最小二乘回归的一种补充,它损失了无偏性,来换取高的数值稳定性,从而得到较高的计算精度。通常岭回归方程的R平方值会稍低于普通回归分析,但回归系数的显著性往往明显高于普通回归,在存在共线性问题和病态数据偏多的研究中有较大的实用价值。
(4)KNN
给一个新的数据时,离它最近的 k 个点中,哪个类别多,这个数据就属于哪一类
7.项目梳理
(1)交通标志分类识别
from Keras.models import Sequential
CLASSES_NUM = 62
image_size是32*32
init_lr = 1e-3
bs = 32
EPOCHS = 35
共有50000 张图像,分训练集 40000 个图像,测试集有 10000 个图像,62个文件夹分好。
1.导入数据:图像大小处理,类型变化(变成keras),图片和标签建两个元组,归一化
2.网络模型:model.add自由添加组件模块,3个(5,5)卷积层,不补0,激活函数是relu,池化层(2,2),歩长是2;2个全连接层,1个激活函数是relu,最后一个是激活函数softmax
3.训练:优化器:adam,compile,fit
def train(aug, trainX, trainY, testX, testY):
print(“[INFO] compiling model…”)
model = Triffic_Net.build(width=image_size, height=image_size, depth=3, classes=CLASSES_NUM)
opt = Adam(lr=init_lr, decay=init_lr/EPOCHS)
model.compile(loss=’categorical_crossentropy’, optimizer=opt, metrics=[‘accuracy’])
print(“[INFO] training network…”)
H = model.fit_generator(aug.flow(trainX, trainY, batch_size=bs),
validation_data=(testX, testY), steps_per_epoch=len(trainX)//bs,epochs=EPOCHS, verbose=1)
loss:0.09,acc:96%
4.保存导出模型:iris_model.h5,class.model
5.导入图片进行预测
(2)车辆图像识别
项目简介:
10 种不同的车型,有巴士,出租车,货车,家用轿车,面包车,吉普车,运动型多功能车,重型货车,赛车,消防车。每个类型有 200 张高像素图像,共有 2000 张训练集。智能交通中需要对车型进行识别,而为后续的决策算法进行输入。
项目总结:
图片文件名修改,改变图片大小
dropout是0.25
图像进行预处理(打标签文件改名,图像增强,图像旋转和大小修改),使用基于TensorFlow 框架下 layer 模块,搭建基础的 CNN,导入数据,进行训练,导出模型,进行测 试集数据测试,准确率只有 46%。 修改迭代次数等参数没有明显优化,学习率由 1e-2 改成 0.001,准确率变成 55%。之后采用 inception_V3 预训练模型和其网络模型代码,导入数据,训练得到 pb 文件,之后调用测试 200 张图片,Top5 准确率达到 96%。
#计算有多少类图片
num_classes = len(set(labels))
#定义placeholder,存放输入和标签
datas_placeholder = tf.placeholder(tf.float32, [None, 32, 32, 3])
labels_placeholder = tf.placeholder(tf.int32, [None])
#存放Dropout参数的容器, 训练时为0.25,测试时为0
dropout_placeholder = tf.placeholder(tf.float32)
#定义卷积层,20个卷积核,卷积核大小是5,用Relu激活
conv0 = tf.layers.conv2d(datas_placeholder, 20, 5, activation=tf.nn.relu)
#定义max_pooling层,pooling窗口是2×2,步长是2×2
pool0 = tf.layers.max_pooling2d(conv0, [2, 2], [2, 2])
#定义卷积层,40个卷积核,卷积核大小是4,用Relu激活
conv1 = tf.layers.conv2d(pool0, 40, 4, activation=tf.nn.relu)
#定义max_pooling层,pooling窗口是2×2,步长是2×2
pool1 = tf.layers.max_pooling2d(conv1, [2, 2], [2, 2])
#定义卷积层,60个卷积核,卷积核大小是3,用Relu激活
conv2 = tf.layers.conv2d(pool1, 60, 3, activation=tf.nn.relu)
#定义max_pooling层,pooling窗口是2×2,步长是2×2
pool2 = tf.layers.max_pooling2d(conv2, [2, 2], [2, 2])
#将3维特征转换为1维向量
flatten = tf.layers.flatten(pool2)
#全连接层,转换为长度为100的特征向量
fc = tf.layers.dense(flatten, 400, activation=tf.nn.relu)
#加上dropout,防止过拟合
dropout_fc = tf.layers.dropout(fc, dropout_placeholder)
#未激活的输出层
logits = tf.layers.dense(dropout_fc, num_classes)
predicted_labels = tf.arg_max(logits, 1)
#利用交叉熵定义损失
losses = tf.nn.softmax_cross_entropy_with_logits(labels=tf.one_hot(labels_placeholder, num_classes), logits=logits)
#平均损失
mean_loss = tf.reduce_mean(losses)
#定义优化器, 指定要优化的损失函数
optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(losses)
#用于保存和载入模型
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
train_feed_dict = {
datas_placeholder:datas,
labels_placeholder:labels,
dropout_placeholder:0.5
}
for step in range(150):
_,mean_loss_val = sess.run([optimizer, mean_loss], feed_dict=train_feed_dict)
if step % 10 == 0:
print(“step = {} t mean loss = {}”.format(step, mean_loss_val))
saver.save(sess, model_path)
预测:
with tf.Session() as sess:
print(‘测试模式’)
saver.restore(sess, model_path)
print(‘从{}载入模型 ‘.format(model_path))
#label和名称的对照关系
label_name_dict = {
0:’巴士’,
1:’出租车’,
2:’货车’,
3:’家用轿车’,
4:’面包车’,
5:’吉普车’,
6:’运动型多功能车’,
7:’重型货车’,
8:’赛车’,
9:’消防车’
}
test_feed_dict = {
datas_placeholder:datas,
labels_placeholder:labels,
dropout_placeholder:0
}
predicted_labels_val = sess.run(predicted_labels, feed_dict=test_feed_dict)
#真实label和模型预测label
for fpath, real_label, predicted_label in zip(fpaths, labels, predicted_labels_val):
real_label_name = label_name_dict[real_label]
predicted_label_name = label_name_dict[predicted_label]
print(‘{}t{} => {}’.format(fpath, real_label_name, predicted_label_name))
correct_number = 0
for fpath, real_label, predicted_label in zip(fpaths, labels, predicted_labels_val):
if real_label == predicted_label:
correct_number += 1
correct_rate = correct_number/200
print(‘正确率:{:.2%}’.format(correct_rate))
(3)车辆检测
参考这个https://www.cnblogs.com/qcloud1001/p/7677661.html就行
(4) 多标签服装与颜色图像识别(智慧零售)
项目简介:
2167 个图像,6 个类别(Black Jeans,Blue Dress,Blue Jeans,Red Dress,Red Shirt),使用图
像识别技术进行多标签识别,对服装图像进行服装类型和颜色的分类。
项目总结:
基于 Keras 和 Sklearn 实现多标签分类,首先对图像进行预处理(图像增强,图像旋转和大小修改),搭建 FashionNet 来同时分类一张图像的两个独立标签,数据集划分train:test=8:2,然后在本地进行训练。利用 tensorboard 实时监控训练过程,根据 loss 的下降情况和其他监控数据进行调参,训练结束- loss: 0.0541 – accuracy: 0.9812 – val_loss: 0.0609 – val_accuracy: 0.9828,使用导出 model 文件进行最终的结果检测,可以识别图像的服装类型
和颜色。
class FashionNet:
@staticmethod
def build(width, height, depth, classes, finaAct=’softmax’):
model = Sequential()
inputShape = (height, width, depth)
chanDim = -1
if K.image_data_format() == ‘channels_first’:
inputShape = (depth, height, width)
chanDim = 1
model.add(Conv2D(32, (3,3), padding=’same’, input_shape=inputShape))
model.add(Activation(‘relu’))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding=’same’, input_shape=inputShape))
model.add(Activation(‘relu’))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding=’same’, input_shape=inputShape))
model.add(Activation(‘relu’))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3, 3), padding=’same’, input_shape=inputShape))
model.add(Activation(‘relu’))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding=’same’, input_shape=inputShape))
model.add(Activation(‘relu’))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation(‘relu’))
model.add(BatchNormalization())
model.add(Dropout(0.5))
model.add(Dense(classes))
model.add(Activation(finaAct))
return model
EPOCHS = 15
INIT_LR = 1e-3
BS = 32
IMAGE_DIMS = (96, 96, 3)
model.fit_generator(aug.flow(trainX, trainY, batch_size=BS), validation_data=(testX, testY), steps_per_epoch=len(trainX)//BS, epochs=EPOCHS, verbose=1, callbacks=[TensorBoard(log_dir=’mytensorboard’)])
要去面试了,加油吧!
本文来自爱汐投稿,不代表胡巴网立场,如若转载,请注明出处:https://www.hu85.com/268560.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 xxxxx@qq.com 举报,一经查实,本站将立刻删除。